Spark 作业的基本运行原理
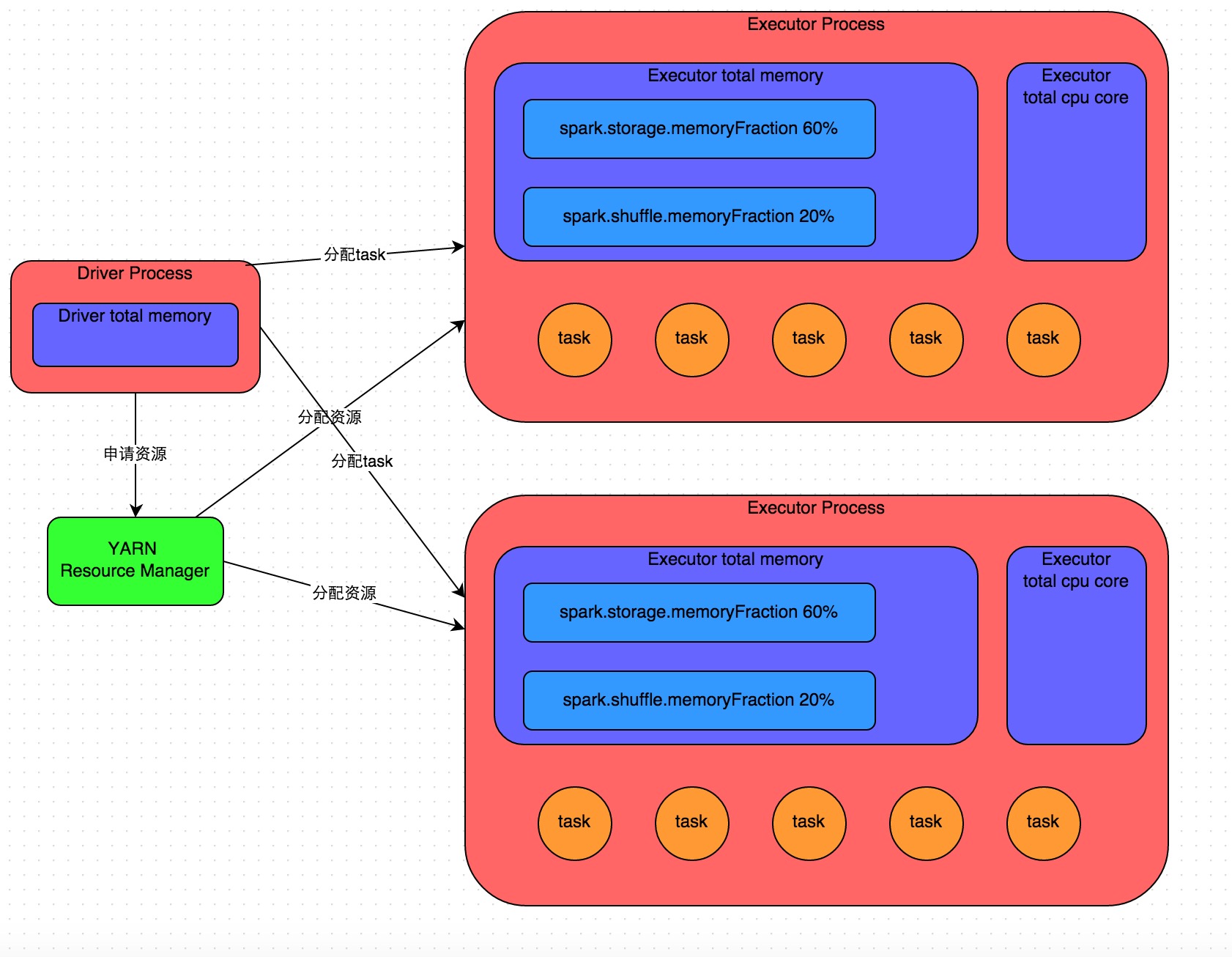 如图中所示,提交作业后会启动一个 Driver 进程(本地或集群节点上,取决于 deploy-mode),Driver 首先去资源管理器(如 YARN)要资源,让集群在多台机器上启动多个 Executor 进程。每个 Executor 都有自己的内存和 CPU 核心。然后Driver 把你的代码拆成多个阶段(stage),再把每个阶段切成很多最小计算单元(task),分发到各个 Executor 去并行执行。每个 task 都跑同一段逻辑,但处理的数据分片不同。一个阶段的所有 task 完成后,会把中间结果写到各节点本地磁盘;然后Driver就会调度运行下一个stage。Stage 的划分是根据 Shuffle 类型的算子来进行划分的,Shuffle 类型的算子包括
如图中所示,提交作业后会启动一个 Driver 进程(本地或集群节点上,取决于 deploy-mode),Driver 首先去资源管理器(如 YARN)要资源,让集群在多台机器上启动多个 Executor 进程。每个 Executor 都有自己的内存和 CPU 核心。然后Driver 把你的代码拆成多个阶段(stage),再把每个阶段切成很多最小计算单元(task),分发到各个 Executor 去并行执行。每个 task 都跑同一段逻辑,但处理的数据分片不同。一个阶段的所有 task 完成后,会把中间结果写到各节点本地磁盘;然后Driver就会调度运行下一个stage。Stage 的划分是根据 Shuffle 类型的算子来进行划分的,Shuffle 类型的算子包括 groupByKey、reduceByKey、join、cogroup 等。下一个stage的task的输入数据就是上一个stage输出的中间结果。如此循环往复,直到将我们自己编写的代码逻辑全部执行完,并且计算完所有的数据,得到我们想要的结果为止。
常用函数
时间函数
时间函数是在开发中最常用的函数之一了,因为很多的分区都使用的是时间分区,以及时间有各种各样的格式以及需要进行各种计算,所以熟练的掌握时间的处理可以极大的提高我们的开发效率。
to_date:返回日期字符串的日期值。只针对特定格式的日期字符串,例如 yyyy-MM-dd 不支持 yyyyMMdd。
SELECT to_date('2025-11-26 10:32:00') AS date;
-- 输出:2025-11-26
SELECT to_date('20251126') AS date;
-- 输出 NULLfrom_unixtime:转化当前时间戳为日期字符串。
第一个参数为10位的时间戳,如果是13位必须cast(13位时间戳/1000 as bigint) 转换后再进行实践转换
SELECT from_unixtime(1700998320) AS date;
-- 输出:2025-11-26 10:32:00
SELECT from_unixtime(1700998320000,'yyyy-MM-dd HH:mm:ss') AS date;
-- 输出:2025-11-26 10:32:00unix_timestamp:返回日期字符串的时间戳。
SELECT unix_timestamp('2025-11-26 10:32:00') AS timestamp;
-- 输出:1700998320
SELECT unix_timestamp('20251126','yyyyMMdd');
-- 输出:1764115200条件函数
if: 三目运算符,根据条件返回不同的值。
SELECT if(1=1,'true','false') AS result;
-- 输出:true
SELECT if(1=2,'true','false') AS result;
-- 输出:falsecase when: 多分支条件判断,根据不同的条件返回不同的值。
SELECT case when 1=1 then 'true' when 1=2 then 'false' else 'unknown' end AS result;
-- 输出:true
SELECT case when 1=2 then 'true' else 'false' end AS result;
-- 输出:falsecase when 语法是有短路求值的,如果满足第一个when 判断条件,就不会继续往下判断,这点需要注意,如果满足多个when条件,优先取的值when要放在前面。
coalesce:返回第一个非空值。如果所有参数都是空值,返回空值。
SELECT coalesce(null,'a','b','c') AS result;
-- 输出:a
SELECT coalesce(null,null,null) AS result;
-- 输出:nullnvl:如果第一个参数为null,返回第二个参数;否则返回第一个参数。
SELECT nvl(null,'a') AS result;
-- 输出:a
SELECT nvl('b','a') AS result;
-- 输出:b数值计算函数
rand:返回一个0到1之间的随机数,也可以用于随机取样。
SELECT rand() AS random_number;
-- 输出:0.12345678901234567890例如我们想获取随机的1000 条数据
SELECT * FROM table_name
order by rand()
limit 1000round:四舍五入到指定的小数位数。
SELECT round(1.2345,2) AS result;
-- 输出:1.23ceil:向上取整,返回大于或等于该值的最小整数。
SELECT ceil(1.2345) AS result;
-- 输出:2floor:向下取整,返回小于或等于该值的最大整数。
SELECT floor(1.2345) AS result;
-- 输出:1窗口函数
窗口函数是在 SQL 中用于对结果集进行分组计算的函数。它可以在不改变结果行数的情况下,为每一行添加额外的计算结果。窗口函数通常与 OVER 子句一起使用,用于指定窗口的范围和分区。
相对位置函数
lead: 返回分组内当前行后面的第n行的值。如果当前行后面没有足够的行,则返回 NULL。
SELECT lead(salary,1) OVER (PARTITION BY dept ORDER BY uid) AS next_salary;lag: 返回分组内当前行前面的第n行的值。如果当前行前面没有足够的行,则返回 NULL。
SELECT lag(salary,1) OVER (PARTITION BY dept ORDER BY uid) AS prev_salary;lead和lag 函数通常可以用于去计算波峰波谷,例如常见的面试题如下:找到价格波动的波峰和波谷。
| item_id | time_point | price | 备注 |
|---|---|---|---|
| item_001 | 2023-12-01 10:00 | 100 | 初始价格 |
| item_001 | 2023-12-01 10:01 | 120 | 上升 |
| item_001 | 2023-12-01 10:02 | 150 | 波峰 (前值120,后值130) |
| item_001 | 2023-12-01 10:03 | 130 | 下降 |
| item_001 | 2023-12-01 10:04 | 110 | 下降 |
| item_001 | 2023-12-01 10:05 | 80 | 波谷 (前值110,后值90) |
| item_001 | 2023-12-01 10:06 | 90 | 上升 |
| item_001 | 2023-12-01 10:07 | 90 | 平稳 |
| item_001 | 2023-12-01 10:08 | 160 | 波峰 (前值90,后值100) |
| item_001 | 2023-12-01 10:09 | 100 | 剧烈下降 |
我们可以用下面的方法来判断:
SELECT *,
CASE
WHEN lead_time_price>price AND lag_time_price>price THEN '波谷'
WHEN lead_time_price<price AND lag_time_price<price THEN '波峰'
END price_type
FROM (
SELECT *,
lead(price, 1) OVER (PARTITION BY item_id ORDER BY time_point ) AS lead_time_price,
lag(price, 1) OVER ( PARTITION BY item_id ORDER BY time_point ) AS lag_time_price
FROM t_price_history
)排名函数
first_value:返回分组内的第一个值。
SELECT first_value('a') OVER (PARTITION BY 1 ORDER BY 1) AS result;
-- 输出:alast_value:返回分组内的最后一个值。
在 SQL 标准中,如果你没有显式指定窗口范围(ROWS/RANGE ...),LAST_VALUE 的默认窗口范围通常是:RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW(从分区的起始行到当前行)这意味着:默认情况下,LAST_VALUE 取的是 “当前行” 的值,而不是整个分区的最后一个值。 这往往不是用户想要的结果。所以,一般来说 不推荐使用last_value 可以使用first_value将数据倒序排序后来实现
| dept | uid | salary |
|---|---|---|
| A | 1 | 100 |
| A | 2 | 200 |
| A | 3 | 300 |
对于这样的数据,例如我们想要获得A 部门的最后一个 uid 的数据,我们一般会使用如下的方法
LAST_VALUE(salary) OVER (PARTITION BY dept ORDER BY uid)但是由于last_value 默认窗口是分区的起始到当前行,所以其计算过程如下:
计算过程:
- 当处理
id=1时,窗口范围是id=1到id=1。最后一个值是 100。 - 当处理
id=2时,窗口范围是id=1到id=2。最后一个值是 200。 - 当处理
id=3时,窗口范围是id=1到id=3。最后一个值是 300。 - 结果:你得到的结果和
salary列本身一模一样,而不是你期望的每一行都是 300。
所以我们可以通过三个方法来解决:
- 显式指定窗口范围:
LAST_VALUE(salary) OVER (PARTITION BY dept ORDER BY uid ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING)- 使用
first_value将数据倒序排序后取第一个值:
FIRST_VALUE(salary) OVER (PARTITION BY dept ORDER BY uid DESC)- 使用
max函数:
MAX(salary) OVER (PARTITION BY dept)聚合函数
sum: 对分组内的数值进行求和。
with t(dept,uid,salary) as (
select 'A', 1, 100 union all
select 'A', 2, 200 union all
select 'A', 3, 300 union all
select 'B', 1, 400 union all
select 'B', 2, 500
)sum 的Order By 子句是可选的。如果不指定Order By 子句,那么sum 函数会对分组内的所有行进行求和。如果指定了Order By 子句,那么sum 函数会对分组内的行按照Order By 子句进行排序后再求和。所以排序后的求和是分组内的累计到当前行的和。
select
dept,
sum(salary) over (partition by dept order by uid) as cum_salary
from t+-------+-------------+
| dept | cum_salary |
+-------+-------------+
| A | 100 |
| A | 300 |
| A | 600 |
| B | 400 |
| B | 900 |
+-------+-------------+select
dept,
sum(salary) over (partition by dept order by uid) as cum_salary
sum(salary) over (partition by dept) as cum_salary
from t+-------+-------------+
| dept | cum_salary |
+-------+-------------+
| A | 600 |
| A | 600 |
| A | 600 |
| B | 900 |
| B | 900 |
+-------+-------------+任务优化
数据倾斜
数据倾斜是指在Spark计算过程中,由于数据分布不均匀,导致某些节点处理的数据量远超其他节点,形成计算负载的 "长尾效应" 。这种现象会显著降低集群整体吞吐量,甚至引发OOM导致任务失败。
数据倾斜发生的现象: 绝大多数task执行得都非常快,但个别task执行极慢。比如,总共有1000个task,997个task都在1分钟之内执行完了,但是剩余两三个task却要一两个小时。这种情况很常见。具体的体现我们可以从Spark 的 web UI 或者metris 中查看。
- 查看 metris 中的 CPU 和内存的使用情况,看看是否有
长尾效应。 - 查看 Spark 的 web UI 中的 Stage Tab,看看是否有Max 处理的数据量和时间明显偏大,如果有的话那就说着在这个 Stage 中发生了
数据倾斜。
数据倾斜发生的原理: 在进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,比如按照key进行聚合或join等操作。此时如果某个key对应的数据量特别大的话,就会发生数据倾斜。比如大部分key对应10条数据,但是个别key却对应了100万条数据,那么大部分task可能就只会分配到10条数据,然后1秒钟就运行完了;但是个别task可能分配到了100万数据,要运行一两个小时。因此,整个Spark作业的运行进度是由运行时间最长的那个task决定的。

背压
详见--> Flink 背压
注意事项
常见的数据注意事项
- 区分NULL、'' (空字符串)。NULL 是用 is null、is not null 来查询;''是用 ='' 、!=''来查询。
- 注意 where !=会将NULL值过滤掉
- and 优先级比 or 高 。用or的时候要注意用括号,来保障正确语义
- 字符串比较不同于整型比较,是从左到右顺序进行比较。 在同一位置出现某一个字符不同,即可区分两个字符串的大小,如果各位置相同,字符数多的大。
避免使用 distinct
Hive count(distinct xxx)只产生一个reduce,这就造成了所有map端传来的数据都在一个tasks中执行,成为了性能瓶颈。(简单来说就是无法发挥分布式计算的优势,本应多台机器完成的事情,只能一台机器去工作)。所以我们要先了解数据,判断是否必须使用 distinct,如果要使用distinct,也可以使用 group by 来进行代替。例如下面的案例:
使用 distinct
SELECT DISTINCT colA, colB, colC
FROM my_table;使用 group by 代替 distinct:
SELECT colA, colB, colC
FROM my_table
GROUP BY colA, colB, colC;Flink 流式计算
两阶段提交
两阶段提交(Two-Phase Commit,简称 2PC) ,就是为了去完成我们常说的 " Exactly Once" 语义。即如何保证 Flink 内部的处理结果和外部系统(比如 Kafka、MySQL)的数据状态是完全一致的?。2PC 主要分为了两个阶段,分别如下:
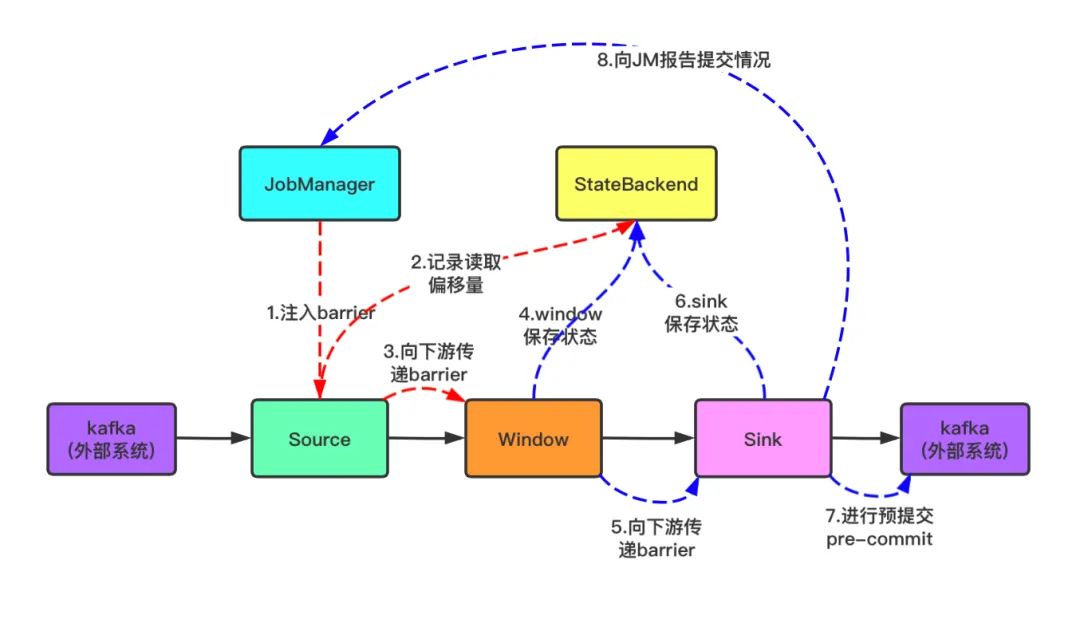
- 预提交阶段(Pre-Commit Phase): JobManager 向所有 Source(数据源)发送一个令牌(Barrier)。这个令牌会随着数据流向下游传递,当数据流到 Sink 输出端的时候,Sink 会开启一个事务,将数据写入进去,但是此时属于不可见的状态,每一个算子都将状态保存到状态后端,并回复给 JobManager ACK 确认。
- 确认阶段(Commit Phase): 当 JobManager 收到所有算子的 ACK 确认后,会向所有算子发送一个提交事务的指令。算子收到指令后,会将数据写入到外部系统中,并且确认事务完成。如果在提交事务的过程中发生了异常,比如网络分区、超时等,JobManager 会向所有算子发送一个回滚事务的指令。算子收到指令后,会撤销之前写入的数据,并且回复 JobManager 确认回滚完成。
结合下文的 Checkpoint 的原理,就会发现 2PC 与 CheckPoint 是息息相关的,实际上 2PC 的预提交阶段就是 Checkpoint 的触发阶段,确认阶段就是 Checkpoint 的提交阶段。
状态管理
状态后端
Checkpoint
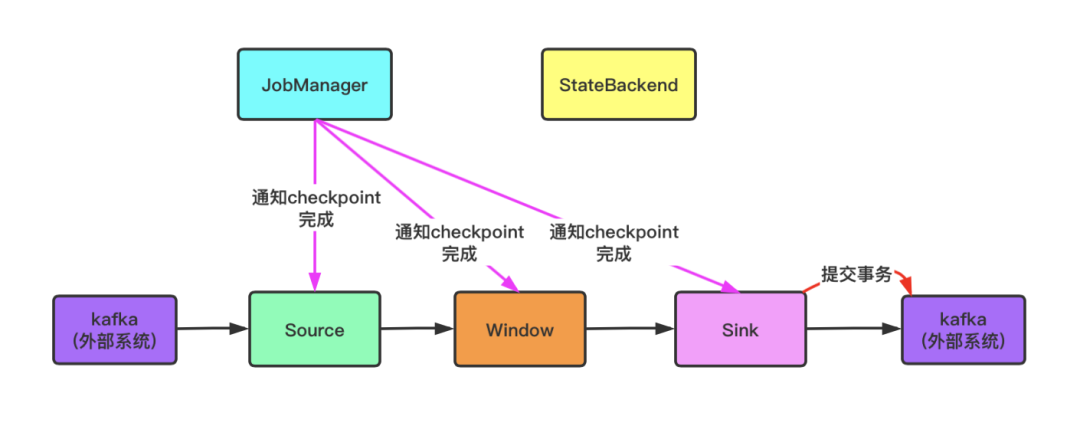
Checkpoint(检查点) 是 Flink 中用于实现 Exactly-Once 语义的重要机制。它的基本原理是:当一个算子需要进行状态 checkpoint 时,它会 将当前的状态(包括算子的本地状态和外部系统的状态)保存到一个持久化存储(如 HDFS、S3 等)中。 同时,它会向 JobManager 发送一个确认消息,确认 checkpoint 已经完成。如果在 checkpoint 过程中发生了故障,JobManager 会触发一个回滚操作,将所有算子的状态恢复到 checkpoint 之前的状态。
Checkpoint实现原理: JobManager 向所有 Source(数据源)发送一个令牌(Barrier)。这个令牌会随着数据流向下游传递,当 Source 算子收到令牌后,会将当前的状态保存到状态后端。同时,它会向 JobManager 发送一个确认消息,确认 checkpoint 已经完成。当 JobManager 收到所有算子的确认消息后,即认为 checkpoint 完成。
双流Join
双流 join 也是在 Flink 作业的开发中常见的一种操作。毕竟我们平时写离线作业的时候就经常需要将作业进行 join 操作,将两个不同的数据集根据某个共同的字段进行关联。而在 Flink 中,双流 join 操作的实现原理与离线作业中的 join 操作类似,都是通过将两个数据集根据共同的字段进行关联,然后将关联结果输出到下游算子进行处理。这里将双流 Join 划分为了 3 中方式:基于时间的 join,基于窗口的 join,三流 join
基于时间的 join:两个流中相同的键值以及时间戳不超过某一范围的数据做 join,也是 Flink 作业中默认的 join 方式,例如下面的案例:
SELECT
o.order_id,
o.order_time,
s.ship_time,
o.price
FROM Orders o
JOIN Shipments s ON o.order_id = s.order_id
WHERE s.ship_time BETWEEN o.order_time AND o.order_time + INTERVAL '4' HOUR;基于窗口的 join:将两个流的数据输入到公共窗口中进行 join
必须保证两条流的 window_start 和 window_end 完全一致,才能在窗口结束时触发 Join。
SELECT
L.ad_id,
L.window_start,
L.window_end,
L.click_count,
R.view_count
FROM (
-- 这里的 ClickTable 和 ViewTable 已经通过 Window TVF 进行了开窗
SELECT * FROM TABLE(TUMBLE(TABLE ClickTable, DESCRIPTOR(rowtime), INTERVAL '1' MINUTES))
) L
JOIN (
SELECT * FROM TABLE(TUMBLE(TABLE ViewTable, DESCRIPTOR(rowtime), INTERVAL '1' MINUTES))
) R
ON L.ad_id = R.ad_id AND L.window_start = R.window_start AND L.window_end = R.window_end;三流 join:将双流 join 的结果保存到 Redis,再和第三个流进行 join
水位线
水位线(Watermark)是 Flink 中用于处理乱序事件时间(Event Time)的重要机制。它的基本原理是:当一个算子需要处理事件时间为 T 的数据时,它会先检查是否存在一个水位线为 T 的记录。如果存在,说明所有时间戳小于等于 T 的数据都已经到达,未来不会再有比 T 更早的数据了。因此,算子可以安全地处理时间戳为 T 的数据。
但是这里需要注意的是Flink 的一个DataStream 或者 Table 只能有一个活跃的水位线生成逻辑,
所以当需要使用同一个源计算不同的需求的时候, 需要将数据源转换为两个逻辑流 ,每个流里拥有自己独立的时间线。见下面的例子:
-- 原始 Kafka 表,不直接定义水印
CREATE TABLE raw_orders (
order_id STRING,
order_time TIMESTAMP(3),
pay_time TIMESTAMP(3),
...
) WITH (...);
-- 视图 1:以下单时间为基准
CREATE VIEW view_order_time AS
SELECT *, WATERMARK FOR order_time AS order_time - INTERVAL '5' SECOND
FROM raw_orders;
-- 视图 2:以支付时间为基准
CREATE VIEW view_pay_time AS
SELECT *, WATERMARK FOR pay_time AS pay_time - INTERVAL '5' SECOND
FROM raw_orders
WHERE pay_time IS NOT NULL; -- 排除未支付的数据,防止水印停滞
-- 统计下单量
INSERT INTO sink_table_a
SELECT window_start, window_end, COUNT(order_id)
FROM TABLE(TUMBLE(TABLE view_order_time, DESCRIPTOR(order_time), INTERVAL '1' HOURS))
GROUP BY window_start, window_end;
-- 统计支付量
INSERT INTO sink_table_b
SELECT window_start, window_end, COUNT(order_id)
FROM TABLE(TUMBLE(TABLE view_pay_time, DESCRIPTOR(pay_time), INTERVAL '1' HOURS))
GROUP BY window_start, window_end;反压
详见--> Flink 背压
Flink 作业检查与调整
数开思想
Flink 数据流的思想
Flink 数据流(Dataflow)模型最本质的特征就在于一个 “流” 字。不仅业务数据在流动,控制信号也在流动。Flink 将控制逻辑内化为特殊的数据包,注入到业务数据流中,使其随数据一同流转。这种设计使得分布式系统中的时间推进、状态一致性等复杂问题变得优雅而高效。以下是这一思想在 Flink 核心机制中的具体体现:
时间推进机制:Watermark(水位线):Watermark 是“流”思想在处理乱序事件时间(Event Time)时的经典应用,Watermark 本质上是一种携带时间戳的特殊数据记录,被源源不断地注入到数据流中,当一个算子接收到时间戳为 TTT 的 Watermark 时,它传达了一个明确的信号:时间戳小于等于 T 的所有数据都已经到达,未来不会再有比 T 更早的数据了。 它随着数据流向下游流动,触发窗口计算的执行。这种机制让系统无需依赖不确定的物理时间,而是通过流动的逻辑时钟来精准控制计算进度。
容错一致性:Checkpoint(检查点):在 Flink 的分布式快照(Checkpoint)机制中,“流”的思想同样得到了淋漓尽致的体现。Barrier(分界线)是一种轻量级的控制记录,由 JobManager 周期性地注入到 Source 端的并行数据流中。Barrier 将数据流切分为“前”和“后”两个部分。Barrier 之前的数据属于当前的 Checkpoint N,而 Barrier 之后的数据属于下一个 Checkpoint N+1。当算子从输入流中接收到 Barrier 时,它明白这是一个信号:现在需要为当前状态制作快照了 算子暂停处理新数据(在 Exactly-Once 语义下需进行 Barrier 对齐),将当前状态异步保存到持久化存储中。保存完毕后,算子向 JobManager 发送 ACK 确认,并将 Barrier 继续广播发送给下游的所有算子。
语法转换思想
在现代软件开发中,无论是大数据计算(如 Spark、Flink),还是前端的内容呈现(如 Markdown、Vue/React 模板),都广泛存在着 “语言转换” 的机制。其核心逻辑在于:开发者使用高抽象级、易于表达的语言(DSL)描述“做什么(What)”,而系统负责将其转换为底层运行时能够理解的“怎么做(How)”。这种从高层抽象到底层执行的转换过程,通常遵循经典的编译管道设计,主要包含以下四个关键阶段:
词法与语法解析 (Lexical Analysis & Parsing):代码-->Token-->AST语法树
将代码字符串拆解为一个个最小的语义单元(Token),例如将 SELECT * 拆解为 SELECT 关键字和 * 符号。根据语法规则,将 Token 组装成抽象语法树(AST, Abstract Syntax Tree)。AST 是代码逻辑的树状结构表示,是后续所有步骤的基础。
语义分析与逻辑计划 (Semantic Analysis & Logical Planning):数据绑定,验证合法性
检查引用的表、字段、变量是否存在,类型是否匹配。将 AST 转换为更通用的逻辑操作树。此时只关心业务逻辑(如“过滤”、“连接”),不关心具体物理实现(如“是用 HashJoin 还是 SortMergeJoin”)。Catalog 介入,验证表名和字段,生成 Analyzed Logical Plan。
优化执行 (Optimization):优化逻辑计划
- 规则优化 (RBO):例如“谓词下推”(Predicate Pushdown),即尽早过滤数据,减少后续计算量。
- 代价优化 (CBO):基于数据量估算,选择代价最小的算法(例如大表 Join 小表时自动选择 Broadcast Join)。
- Catalyst 优化器通过一系列规则将逻辑计划转化为优化后的逻辑计划。
物理计划生成与执行 (Physical Planning & Execution):将计划翻译为目标平台的原生代码并执行。